

自动化收集七星彩数据,Ai分析规律博弈 项目分享
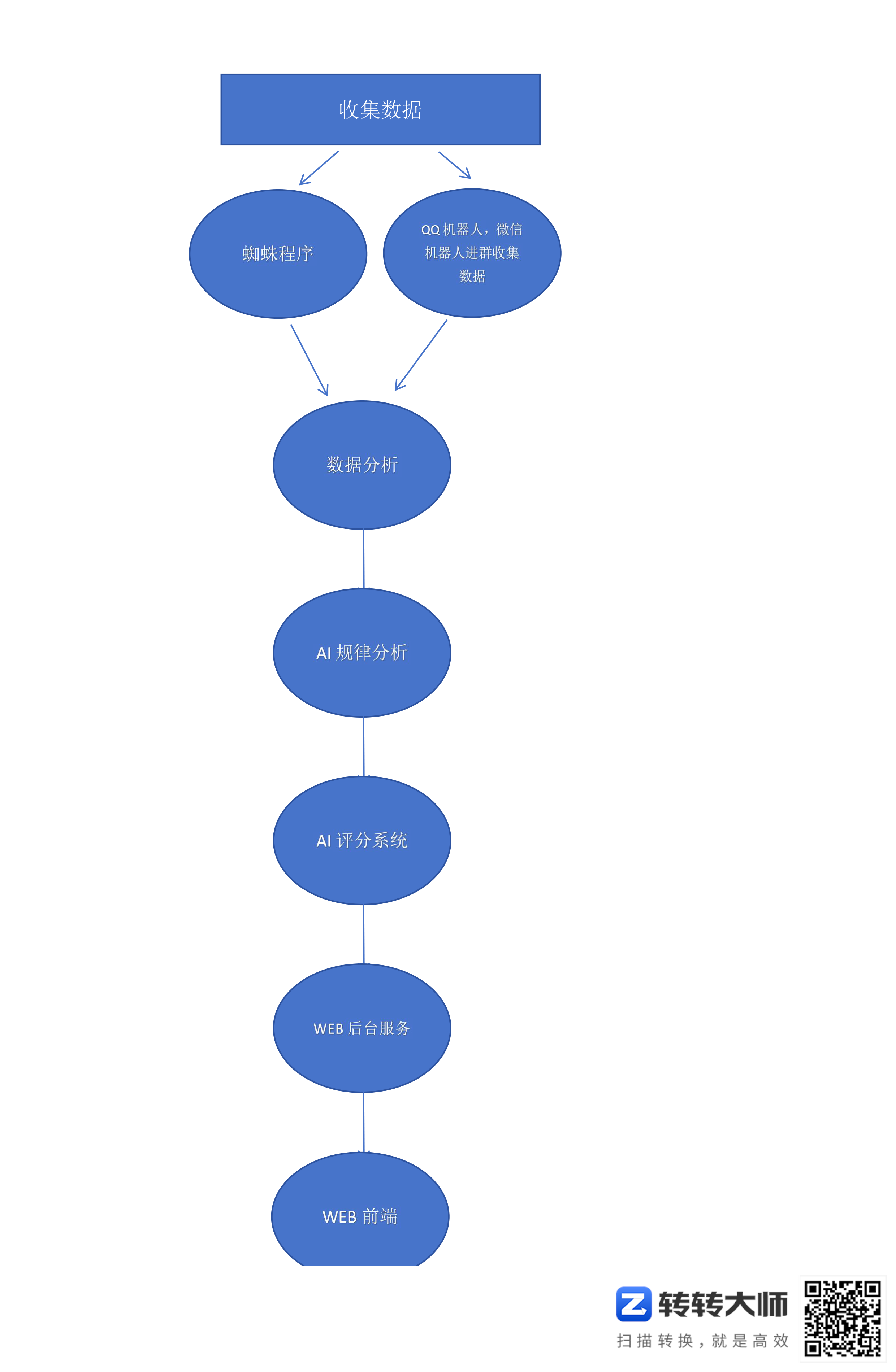
1.写蜘蛛程序在互联网收集本期七星彩票数据。
2.派QQ机器人和微信机器人进七星彩群收集本期数据。
3.写分析数据程序,记录每个号码的个个位置出现的次数,提供给AI分析。
4.写AI分析程序,深度学习分析七星彩规律。
5.写AI评分程序,给每个号码评分,进行博弈。。最终出来结果了xxxxxxxx
6.写WEB后端服务。
7.写WEB前端,最终显示给分析结果给彩民。
欢迎各位彩民朋友们在下面评论给出建议。
有经验的彩民给出一些规律,一些彩票论坛网站,供AI学习。
XPath常用规则 学习分享
XPath 语法:
-
节点选取:
nodename:选择所有指定节点名的子节点。*:通配符,选择所有子节点。@attribute:选择节点的属性。
-
路径表达式:
- 单斜杠
/:从当前节点选取直接子节点。 - 双斜杠
//:从当前节点选取直接子孙节点. .:代表当前节点。..:代表父节点。
- 单斜杠
-
谓语(Predicates):
[condition]:筛选满足指定条件的节点。[position]:选择特定位置的节点,索引从 1 开始。- 可以结合多个条件使用逻辑运算符
and、or、not.
-
文本内容:
text():获取节点的文本内容。string():获取节点及其后代节点的文本内容.
-
函数:
contains(string, substring):检查一个字符串是否包含另一个字符串。starts-with(string, prefix):检查一个字符串是否以指定前缀开头。concat(string1, string2, ...):连接多个字符串。substring(string, start, length):返回字符串的子串。count(nodeset):计算节点集合中节点的数量.
-
轴(Axis):
ancestor:所有祖先节点。parent:父节点。following-sibling:当前节点之后的同级节点。preceding-sibling:当前节点之前的同级节点。self:当前节点自身。child:所有子节点。descendant:所有后代节点。
-
逻辑运算符:
and、or、not:用于组合多个条件。
-
数字比较:
- 等于
=、不等于!=、大于>、小于<、大于等于>=、小于等于<=.
- 等于
这些完整的 XPath 规则和语法可帮助您更好地理解和利用 XPath 在 XML 或 HTML 文档中准确定位和提取所需的节点信息。
基础爬虫实战 学习分享
import requests
import logging
import re
from urllib.parse import urljoin
import json
from os import makedirs
from os.path import exists
import multiprocessing
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
BASE_URL = 'https://ssr1.scrape.center'# 爬取的目标网站的URL
TOTAL_PAGE = 10
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
# 爬取页面html源码
def scrape_page(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
# 页面url
def scrape_index(page):
index_url = f'{BASE_URL}/page/{page}'
return scrape_page(index_url)
# 解析详情页面url
def parse_index(html):
pattern = re.compile('<a.*?href="(.*?)".*?class="name">')
items = re.findall(pattern, html)
if not items:
return []
for item in items:
detail_url = urljoin(BASE_URL, item)
logging.info('get detail url %s', detail_url)
yield detail_url
# 获取详情页面html源码
def scrape_detail(url):
return scrape_page(url)
# 解析详情页面源码
def parse_detail(html):
# 搜索图片模式
cover_pattern = re.compile('class="item.*?<img.*?src="(.*?)".*?class="cover">', re.S)
# 搜索标题模式
name_pattern = re.compile('<h2.*?>(.*?)</h2>')
# 搜索分类模式
categories_pattern = re.compile('<button.*?category.*?<span>(.*?)</span>.*?</button>', re.S)
# 搜索上映日期模式
published_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
# 搜索剧情介绍模式
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>', re.S)
# 搜索评分模式
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>', re.S)
cover = re.search(cover_pattern, html).group(1).strip() if re.search(cover_pattern, html) else None
name = re.search(name_pattern, html).group(1).strip() if re.search(name_pattern, html) else None
categories = re.findall(categories_pattern, html) if re.findall(categories_pattern, html) else None
published = re.search(published_pattern, html).group(1).strip() if re.search(published_pattern, html) else None
drama = re.search(drama_pattern, html).group(1).strip() if re.search(drama_pattern, html) else None
score = float(re.search(score_pattern, html).group(1).strip()) if re.search(score_pattern, html) else None
return {
'cover': cover,
'name': name,
'categories': categories,
'published': published,
'drama': drama,
'score': score
}
# 保存数据
def save_data(data):
name = data.get('name')
encodings = name.replace(':', '')
data['name'] = encodings
data_path = f'{RESULTS_DIR}/{encodings}.json'
json.dump(data, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)
# main
def main(page):
# 获取页面html内容
index_html = scrape_index(page)
# 解析页面电影详情url
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
# 获取详情页面html内容
detail_html = scrape_detail(detail_url)
# 解析详情页面数据
data = parse_detail(detail_html)
logging.info('get data %s', data)
logging.info('saving data to json data')
save_data(data)
if __name__ == '__main__':
# 创建了一个进程池对象,此处未指定进程数量,因此将使用默认值(通常是 CPU 核心数)
pool = multiprocessing.Pool()
# 定义了一个迭代器 pages,从 1 开始直到 TOTAL_PAGE 的范围
pages = range(1, TOTAL_PAGE + 1)
# 使用 pool.map() 将函数 main 应用于每个 pages 中的元素,实现了并行处理。这里假设 main 函数用于处理单个页面的逻辑。
pool.map(main, pages)
# 关闭进程池,不再接受新的任务
pool.close()
# 等待所有进程完成
pool.join()




张海荣
热爱学习,热爱生活。